Kære ligestillingsudvalg
Der er ere og ere fokus på a o y e jo a søg i ge og vi vil derfor ger e præse tere ’HR MATCH'
som
lige er færdigudviklet. Programmet er baseret på machine learning, hvor alder, køn etc. ikke tages med i
overvejelser. Her sammenlignes jobannoncer objektivt med CV og ansøgning gennem systemet. Der findes
dermed et system uden fordomme og med ligestilling på den måde, at det kun vurdere kompetencer og
behandler alle ens. Det gør ingen mennesker
Jeg vil prøve at beskrive vores omtalte produkt og håber det giver god mening. Der er blandt andet dialog
om, at anonyme ansøgninger skal være en del af loven, men hvad er anonym og vi kan nok alle blive enige
om, at det aldrig bliver helt anonymt og objektiv, hvis det ikke er elektronisk. Det næste er, at ansøgerne
aldrig vil blive behandlet på lige fod med menneskeøjne. Vi har nu et system til kvalitetstjek af udvælgelse.
Vi har udviklet en matchmotor, som ikke er tilsvarende noget tidligere udviklet
–
men mange har gjort
forsøget. KL drømmer om at udvikle noget tilsvarende til JobNet, og JobIndex har fået 7 mio. og 3 år af
Innovationsfonden til at lave noget tilsvarende. Ingen af deres systemer har dog ligestilling som et formål.
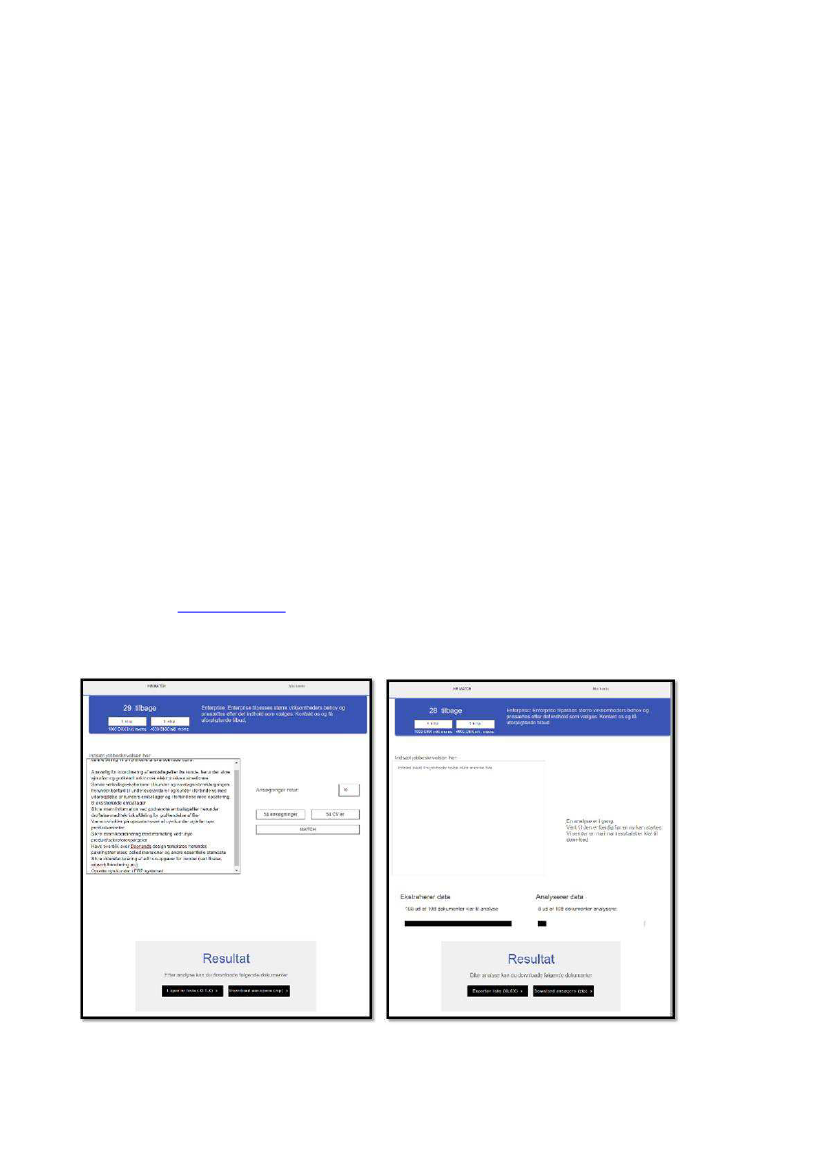
Vores syste hedder HR MATCH og ruges til a alyseri g af jo a o e, v’er og a søg i ger. Syste et
matcher de rigtige kandidater til en specifik opgave bedst muligt. Systemet indlæser opgaven og
kandidaternes CV som fritekst og laver derefter en masse matematiske modeller og beregninger for at
sa
e lig e opgavetekste /jo eskrivelse
ed ka didater es CV’er og jo a søg i g for derved at fi de
ud af, hvor godt hver kandidat matcher og kan prioriteres herefter. Dette bliver udtrykt ved hjælp af en
score, som bruges til at prioritere kandidaterne. Dermed kan du se om kandidater der scorer højest, er de
samme som arbejdsgiveren vælger. Det burde det være, hvis ikke arbejdsgiveren har benyttet mange filtre
til at frasortere kandidater på alder, køn, kriminalitet osv.
Vi har lavet en enkel version, som alle kan benytte. Det er lige meget hvilken størrelse virksomhed der skal
ansætte. Besøg
www.hrmatch.dk
Giv besked, hvis I vil prøve for så opretter jeg jer i systemet.
Nedenstående er screenshots fra de sider